GPU vs TPU vs Ascend: Choosing the Best AI Compute
Learn how GPUs, TPUs, and Ascend NPUs differ for AI training and inference so you can cut costs, speed up models, and pick the right hardware stack.
Learn how GPUs, TPUs, and Ascend NPUs differ for AI training and inference so you can cut costs, speed up models, and pick the right hardware stack.

Is your hardware secretly choking your AI models before they ever reach real potential?
Deep learning isn’t magic, it’s brutal math. Billions of matrix multiplications hammer your hardware. If the wrong chip handles them, your training crawls instead of flies.

CPUs are amazing generalists, but deep learning demands massive parallel matrix crunching. When you scale models, that mismatch quietly burns time, money, and opportunity.
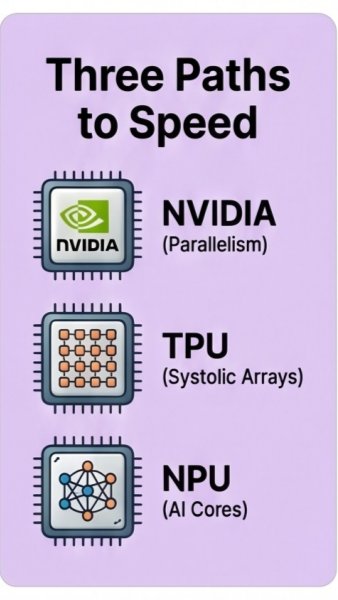
GPUs win with thousands of parallel cores, TPUs use systolic arrays tuned for tensors, and NPUs pack AI-specific cores optimized for efficient matrix pipelines.

Use memory-heavy GPU or TPU setups for huge training runs. For real-time inference on phones or edge devices, lean on NPUs built for ultra-low latency responses.
Mastering GPU, TPU, and Ascend choices turns hardware from bottleneck into unfair advantage. Which stack powers your next AI build?
Discover more insights and resources on our platform.
Visit Kryptomindz