Inside Huawei Ascend: Da Vinci AI Math Engine
Explore how Huawei’s Da Vinci architecture accelerates AI math with matrix engines, on‑chip memory and parallel units to power modern deep learning workloads ef
Explore how Huawei’s Da Vinci architecture accelerates AI math with matrix engines, on‑chip memory and parallel units to power modern deep learning workloads ef

What if AI math ran on hardware designed like a human brain for matrices, not a general-purpose chip?

Deep learning is basically brutal math: billions of tiny matrix multiplications. Standard CPUs and even many GPUs waste energy shuffling data instead of just crunching numbers.
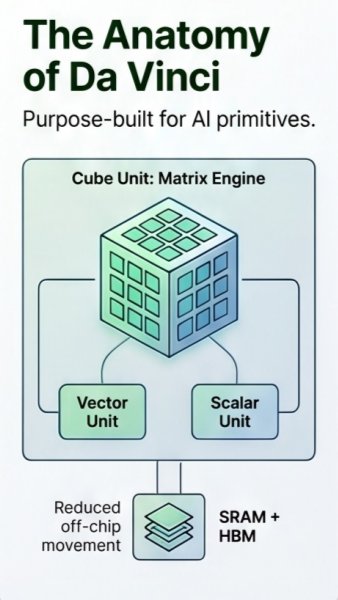
Huawei’s Da Vinci architecture attacks that bottleneck with specialized matrix engines and on-chip memory, so data moves less and math happens faster, especially for giant AI models.
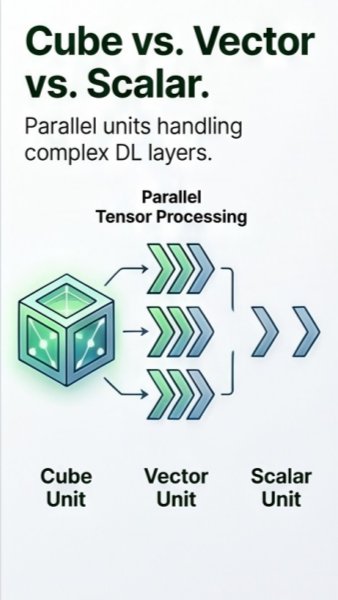
Da Vinci splits the workload: cube units handle dense tensor math, while vector and scalar units process supporting operations in parallel, keeping every part of the chip busy.
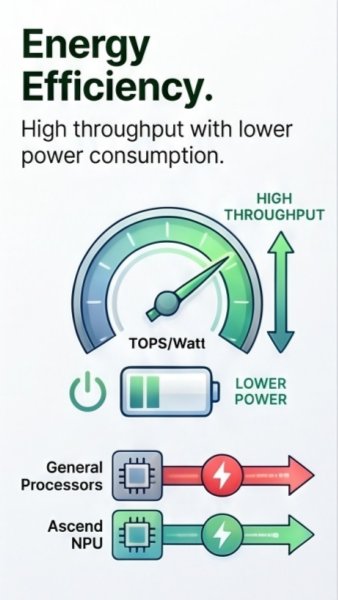
This parallel design boosts throughput per watt, so training or inference workloads finish faster using less power—perfect for data centers, edge AI, and always-on intelligent services.
Discover more insights and resources on our platform.
Visit Kryptomindz