GPU vs TPU vs Ascend: Choosing the Best AI Compute
Learn how GPUs, TPUs, and Ascend NPUs differ for AI training and inference so you can cut costs, speed up models, and pick the right hardware stack.
Learn how GPUs, TPUs, and Ascend NPUs differ for AI training and inference so you can cut costs, speed up models, and pick the right hardware stack.

Your AI model may not be the problem; the real bottleneck is often the hardware running underneath it. A promising computer vision model, large language model, or recommendation engine can feel painfully slow when it is forced onto infrastructure that was never designed for high-volume AI workloads. In practice, this means longer training cycles, delayed experiments, higher cloud bills, and slower product launches. The right AI hardware setup can turn the same model from sluggish and expensive into fast, scalable, and production-ready. Before tuning another hyperparameter, it is worth asking whether your compute stack is limiting the model’s true potential.
Deep learning runs on enormous volumes of mathematical operations, especially matrix multiplications that repeat billions or even trillions of times. Every image classifier, speech model, fraud detection system, or generative AI application depends on hardware that can process these operations efficiently. When deep learning workloads run on chips built for general-purpose tasks, training speed drops and energy consumption rises. This is why AI accelerators such as GPUs, TPUs, and NPUs matter: they are designed to handle parallel computation at scale. Choosing the wrong hardware does not just slow development; it can make ambitious AI projects financially impractical.

CPUs are excellent at handling diverse tasks, from running operating systems to managing application logic, but they are not built to process massive neural network calculations in parallel. Deep learning workloads need thousands of operations happening at the same time, which is where GPUs and other AI accelerators create a major performance gap. For a small prototype, a CPU might be acceptable, but as datasets and model sizes grow, that choice can turn into hours or days of wasted compute time. Businesses feel this gap through missed iteration cycles, delayed model improvements, and higher infrastructure costs. Understanding when to move beyond CPUs is a key step in building scalable AI systems.
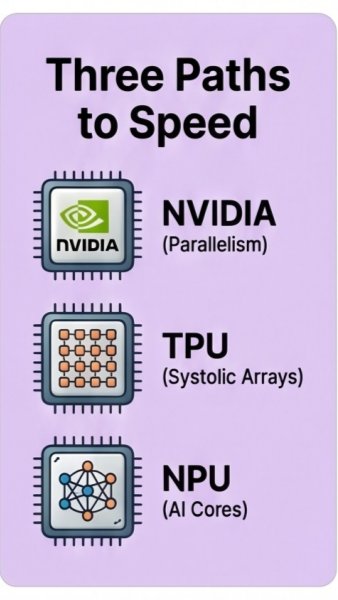
GPUs, TPUs, and Ascend NPUs all accelerate AI, but they do it in different ways. GPUs use thousands of parallel cores, making them highly flexible for training deep learning models, running simulations, and supporting a wide range of AI frameworks. TPUs rely on systolic arrays designed specifically for tensor operations, which makes them powerful for large-scale machine learning workloads in supported cloud environments. Ascend NPUs focus on AI-specific compute pipelines that balance performance and efficiency, especially in ecosystems optimized for Huawei AI infrastructure. Knowing how these chips work helps teams match hardware architecture to the model, framework, and deployment environment they actually use.

Training and inference place very different demands on AI hardware, so the best chip for one stage may not be the best choice for the other. Training large neural networks requires high memory bandwidth, strong parallel compute, and the ability to process massive datasets repeatedly, which often makes GPUs or TPUs the right fit. Inference focuses on delivering predictions quickly and reliably, whether that means a chatbot response, a product recommendation, or real-time object detection on a phone. For edge AI, mobile devices, and low-power environments, NPUs can deliver fast responses without draining batteries or overloading systems. Matching the workload to the chip helps teams avoid overspending while improving user experience.
The best AI teams do not treat hardware as an afterthought; they use compute strategy as a competitive advantage. Selecting the right mix of GPUs, TPUs, and Ascend NPUs can shorten development cycles, lower operating costs, and improve model performance in production. For startups, that may mean faster experimentation without burning through cloud budgets; for enterprises, it can mean scaling AI services reliably across millions of users. The goal is not to chase the most powerful chip, but to choose the hardware that fits your workload, ecosystem, latency needs, and growth plan. When compute choices are intentional, AI infrastructure stops holding you back and starts accelerating everything you build.
Follow the hub for production AI infrastructure, deployment, observability, cost and reliability resources.
Related Service AI Agents & LLMOps DeliveryMove copilots and agents from demos to governed production workflows with monitoring and cost controls.
Implementation Use Case Secure AI Knowledge Operations AgentSee how AI agents can answer, route and govern operational knowledge for teams with traceable controls.
Recommended Course EU AI Act Strategy & LeadershipBuild leadership fluency in AI governance, risk, operating models and practical readiness planning.
YouTube Playlist Production LLMOps ArchitectureWatch the playlist on cutting GenAI costs, latency, failures and production reliability risks.
Book a Discovery Call Map This to Your RoadmapDiscuss how this topic applies to your product, compliance posture, architecture or delivery plan.
Editorial trust
Each KryptoMindz article is reviewed against current enterprise AI, blockchain, digital identity and compliance practices before publication or major updates.
Founder-led perspective from KryptoMindz Technologies, focused on secure AI adoption, Web3 risk, digital identity and enterprise trust architecture.
LinkedIn profileResearch, engineering and advisory work across AI Agents, Enterprise Blockchain, Digital Identity and Digital Trust Engineering.
YouTube channelDiscover more insights and resources on our platform.
Visit Kryptomindz