Inside Huawei Ascend: Da Vinci AI Math Engine
Explore how Huawei’s Da Vinci architecture accelerates AI math with matrix engines, on‑chip memory and parallel units to power modern deep learning workloads ef
Explore how Huawei’s Da Vinci architecture accelerates AI math with matrix engines, on‑chip memory and parallel units to power modern deep learning workloads ef

Deep learning overwhelms conventional CPUs and GPUs because AI workloads are not just occasional calculations; they are massive streams of matrix and tensor operations running nonstop. A CPU is excellent for flexible, general-purpose tasks, but it is not optimized to process billions of repeated AI math operations efficiently. GPUs improved parallel computing, yet many AI models still lose time and energy moving data between memory and compute units. This is why AI chip architecture has shifted toward designs that behave more like specialized math factories, built to accelerate neural network training and inference. For businesses running recommendation engines, computer vision, or generative AI, the right hardware can directly affect speed, cost, and scalability.

Huawei’s Da Vinci architecture is designed around the real bottleneck in deep learning: moving data efficiently while performing high-volume matrix calculations. Instead of relying only on external memory, Da Vinci uses specialized matrix engines and on-chip memory to keep frequently used data close to the compute units. This reduces latency, cuts wasted power, and helps AI models process larger workloads with fewer slowdowns. In practical terms, that can mean faster image recognition in smart cities, smoother natural language processing in cloud applications, and more responsive AI services at the edge. The architecture is especially relevant for organizations trying to run large neural networks without letting infrastructure costs spiral.
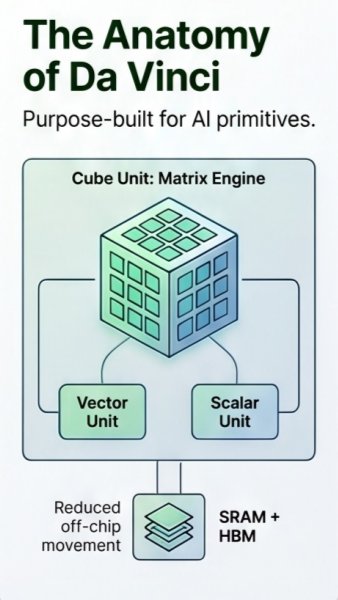
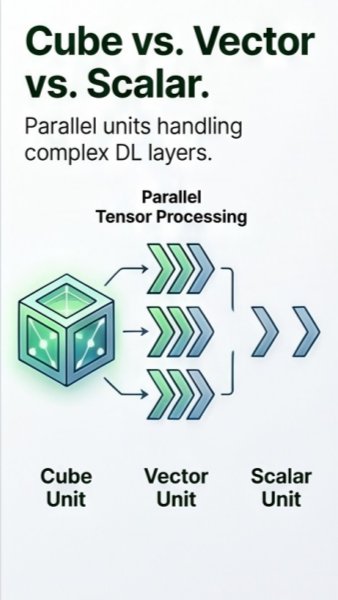
Da Vinci improves AI performance by dividing work across cube, vector, and scalar units instead of forcing one type of processor to handle everything. Cube units focus on dense tensor and matrix multiplication, which forms the backbone of neural network computation. Vector units support operations such as activation functions and normalization, while scalar units handle control logic and lightweight tasks. This workload sharing keeps the chip active and balanced, reducing idle time during both AI training and inference. For developers, the result is a hardware design that can handle complex model pipelines more efficiently, from computer vision systems to enterprise AI assistants.
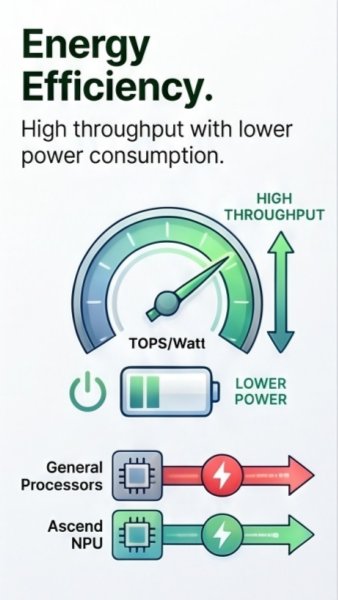
Performance per watt is one of the biggest reasons AI teams care about architectures like Da Vinci. Faster chips are valuable, but power-efficient chips are what make large-scale AI practical in data centers, edge devices, and always-on services. By using specialized processing units and minimizing unnecessary data movement, Da Vinci can deliver more AI throughput for the same energy budget. This matters for companies running high-volume inference, such as fraud detection, personalized recommendations, autonomous systems, or real-time video analytics. Lower power consumption can also reduce cooling needs, operating expenses, and environmental impact over time.
Hardware acceleration only delivers full value when the software stack makes it easy for developers to use. Huawei’s CANN framework connects Da Vinci-based AI processors with popular development environments, helping optimize model execution across training and inference workflows. For teams using frameworks such as PyTorch, this software layer can simplify deployment while improving how workloads map to the underlying AI hardware. A strong pipeline means developers can focus more on model quality and application performance instead of manually tuning every low-level operation. In real-world AI projects, the combination of optimized hardware and a mature software stack can shorten development cycles and improve production reliability.
Follow the hub for production AI infrastructure, deployment, observability, cost and reliability resources.
Related Service AI Agents & LLMOps DeliveryMove copilots and agents from demos to governed production workflows with monitoring and cost controls.
Implementation Use Case Secure AI Knowledge Operations AgentSee how AI agents can answer, route and govern operational knowledge for teams with traceable controls.
Recommended Course EU AI Act Strategy & LeadershipBuild leadership fluency in AI governance, risk, operating models and practical readiness planning.
YouTube Playlist Production LLMOps ArchitectureWatch the playlist on cutting GenAI costs, latency, failures and production reliability risks.
Book a Discovery Call Map This to Your RoadmapDiscuss how this topic applies to your product, compliance posture, architecture or delivery plan.
Editorial trust
Each KryptoMindz article is reviewed against current enterprise AI, blockchain, digital identity and compliance practices before publication or major updates.
Founder-led perspective from KryptoMindz Technologies, focused on secure AI adoption, Web3 risk, digital identity and enterprise trust architecture.
LinkedIn profileResearch, engineering and advisory work across AI Agents, Enterprise Blockchain, Digital Identity and Digital Trust Engineering.
YouTube channelDiscover more insights and resources on our platform.
Visit Kryptomindz