VibeVoice Explained: The New Vibe in AI Audio
This video breaks down how VibeVoice advances AI audio. You’ll learn why traditional text-to-speech feels robotic, what new technology makes voices more natural
This video breaks down how VibeVoice advances AI audio. You’ll learn why traditional text-to-speech feels robotic, what new technology makes voices more natural
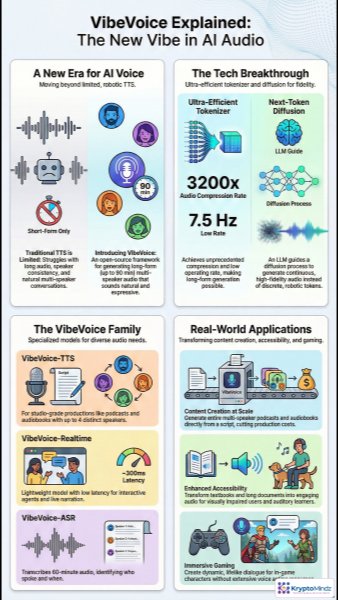
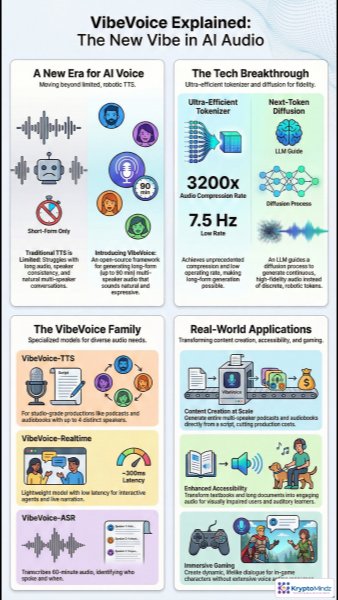
VibeVoice is an AI audio framework designed to make synthetic speech sound less mechanical and more like real human communication. Instead of producing short, flat voice clips, it focuses on expressive, long-form audio that can support storytelling, education, podcasts, and interactive media. This matters because modern audiences expect AI-generated voices to carry emotion, pacing, and personality, especially in content that lasts more than a few minutes. In this overview, you’ll see how VibeVoice improves text-to-speech quality and why its approach could reshape how creators, developers, and accessibility teams produce audio at scale.
Traditional text-to-speech tools often work well for short prompts but can fall apart when generating longer conversations, audiobooks, or podcast-style episodes. Common issues include unnatural pauses, drifting speaker identity, weak emotional delivery, and awkward transitions between different voices. VibeVoice addresses these limitations with an open-source AI voice generation framework built for extended audio, including productions that can run up to ninety minutes. This makes it more practical for realistic dialogue, narrated lessons, multi-character stories, and other use cases where consistency and expressiveness matter.
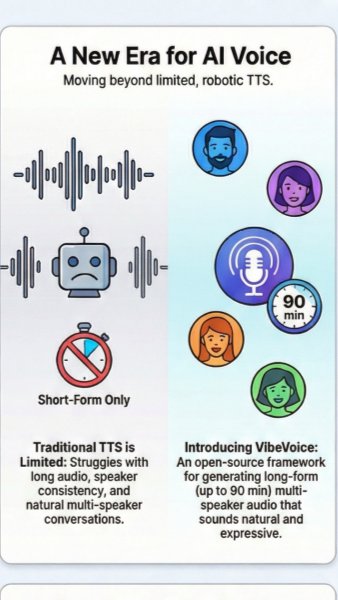
The core breakthrough behind VibeVoice is its combination of efficient audio tokenization and diffusion-based generation. Its tokenizer compresses raw audio dramatically, reducing the amount of data the model needs to process while preserving the details that make speech sound natural. The system then uses a low-rate 7.5 Hz representation to guide a diffusion model, helping it generate smoother, more continuous audio rather than fragmented or artificial-sounding output. By pairing this process with language model guidance, VibeVoice can better capture rhythm, speaker flow, and conversational context in AI-generated speech.
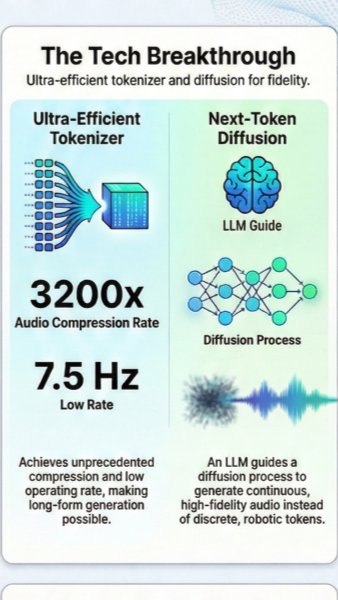
The VibeVoice model family is built around different audio production needs rather than a one-size-fits-all approach. For creators, the narration-focused model can generate studio-style podcasts, audiobooks, or scripted episodes with multiple distinct speakers. For interactive products, the realtime model is optimized for low-latency responses, making it useful for AI agents, live hosts, customer support, or conversational apps. VibeVoice also includes an ASR component that can transcribe long recordings and identify who spoke when, which is valuable for meetings, interviews, lectures, and searchable media archives.
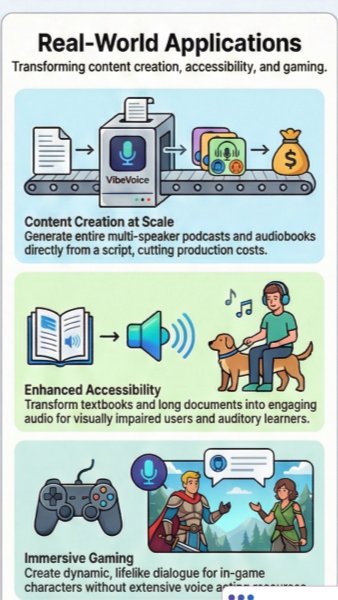
VibeVoice opens practical opportunities across content creation, education, accessibility, and gaming. A creator can turn a written script into a multi-speaker audio production without coordinating studio time, voice actors, or complex recording workflows. Schools and accessibility teams can convert textbooks, training materials, and long documents into engaging audio that is easier for more people to consume. Game developers can use expressive AI voices to build dynamic character dialogue, giving players richer interactions without requiring every line to be pre-recorded. These applications show how advanced AI text-to-speech can reduce production barriers while expanding the kinds of audio experiences teams can deliver.
VibeVoice highlights a broader shift in AI audio from simple voice output to rich, long-form speech experiences. Its efficient tokenization and diffusion-based generation make high-quality voice synthesis more practical for projects that require scale, consistency, and emotional range. With specialized models for narration, realtime interaction, and transcription, it supports a wide range of workflows across media, learning, entertainment, and business communication. For creators and developers, the key value is not just better-sounding speech but the ability to build more immersive audio products faster. As AI voice technology matures, tools like VibeVoice could become a foundation for more natural digital communication.
Discover more insights and resources on our platform.
Visit Kryptomindz