VibeVoice: The AI That Speaks Like Us
This video explores how modern AI transforms robotic, synthetic speech into natural, expressive voices. You’ll learn about market growth, the VibeVoice framewor
This video explores how modern AI transforms robotic, synthetic speech into natural, expressive voices. You’ll learn about market growth, the VibeVoice framewor

Human-like AI voices are rapidly changing what people expect from synthetic speech, moving far beyond flat robotic narration. This section introduces how modern AI voice generation can capture emotion, pacing, pauses, and emphasis in ways that feel more natural to listeners. It also explains why this technology matters across real-world settings, from audiobooks and training videos to accessibility tools and interactive customer support. By exploring the VibeVoice framework and its underlying speech models, you get a clear view of how advanced audio AI turns text and conversation into expressive spoken experiences. The result is a practical look at how natural AI speech is becoming a core layer of digital communication.

The AI voice revolution is being driven by a growing demand for speech that sounds natural, trustworthy, and emotionally aware. Businesses are using AI voice generation for product demos, virtual assistants, e-learning modules, customer service automation, and branded narration at scale. As the market expands from billions to potentially tens of billions of dollars, the focus is shifting from simple text-to-speech tools to full voice experiences that can adapt to context and audience needs. This growth is especially important for industries that rely on clear communication, such as education, entertainment, healthcare, and enterprise productivity. AI-generated voices are no longer just a convenience; they are becoming a competitive advantage for creating faster, more personalized digital content.

VibeVoice introduces a more advanced approach to natural AI speech by combining language understanding with diffusion-based audio generation. Rather than simply converting written text into sound, the system predicts the next segment of audio, helping it preserve rhythm, tone, and conversational flow. This next-token diffusion method is especially useful for long-form speech, where consistency and emotional nuance are difficult to maintain. For example, it can help create podcast-style narration, realistic dialogue, or AI assistants that sound steady and coherent over extended interactions. By modeling speech as an evolving audio sequence, VibeVoice brings AI-generated voices closer to the way people naturally speak and listen.
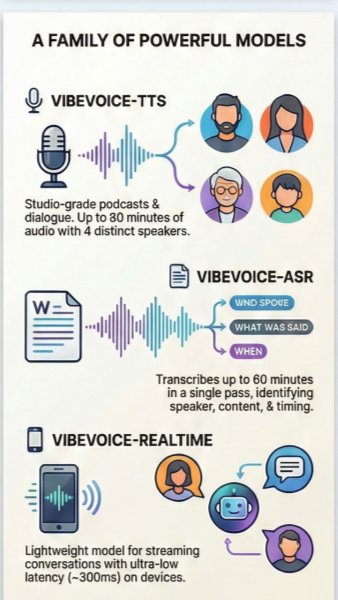
The VibeVoice model family is designed to support different parts of the AI voice pipeline, from creating speech to understanding it in real time. Its text-to-speech models can generate polished narration, character voices, and multi-speaker conversations for content creators and developers. Automatic speech recognition models help turn long recordings into structured transcripts while tracking speaker changes, which is valuable for meetings, interviews, podcasts, and research. Real-time voice models focus on low-latency interaction, making it possible for users to speak naturally with assistants, agents, or applications without awkward delays. Together, these specialized models create a flexible foundation for building voice-enabled products and services.
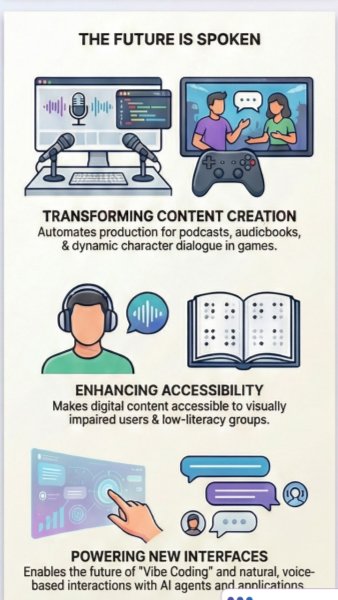
Natural AI voices are opening new possibilities for how content is produced, personalized, and consumed. Podcasters, educators, game developers, and audiobook creators can use AI speech tools to generate drafts, localize content, or experiment with different voices before final production. Accessibility also becomes stronger when people can rely on high-quality spoken interfaces for reading, navigation, learning, and workplace tasks. In software and productivity environments, voice interaction can make it easier to control apps, dictate code, summarize information, and collaborate with AI agents hands-free. As these tools mature, spoken interfaces will become less like a backup option and more like a primary way to create and work.

Voice-first experiences represent the next stage of human-computer interaction, where speaking to technology feels natural instead of transactional. As speech synthesis, recognition, and real-time response systems improve together, digital tools can become more conversational, responsive, and personalized. This shift could reshape everyday tasks such as searching for information, managing schedules, learning new skills, creating content, and collaborating with AI assistants. Instead of navigating complex menus or typing every instruction, users may simply explain what they need and receive spoken guidance or action in return. The future of AI voice technology points toward interfaces that feel less like machines and more like capable collaborators.
Follow the hub for production AI infrastructure, deployment, observability, cost and reliability resources.
Related Service AI Agents & LLMOps DeliveryMove copilots and agents from demos to governed production workflows with monitoring and cost controls.
Implementation Use Case Secure AI Knowledge Operations AgentSee how AI agents can answer, route and govern operational knowledge for teams with traceable controls.
Recommended Course EU AI Act Strategy & LeadershipBuild leadership fluency in AI governance, risk, operating models and practical readiness planning.
YouTube Playlist Production LLMOps ArchitectureWatch the playlist on cutting GenAI costs, latency, failures and production reliability risks.
Book a Discovery Call Map This to Your RoadmapDiscuss how this topic applies to your product, compliance posture, architecture or delivery plan.
Editorial trust
Each KryptoMindz article is reviewed against current enterprise AI, blockchain, digital identity and compliance practices before publication or major updates.
Founder-led perspective from KryptoMindz Technologies, focused on secure AI adoption, Web3 risk, digital identity and enterprise trust architecture.
LinkedIn profileResearch, engineering and advisory work across AI Agents, Enterprise Blockchain, Digital Identity and Digital Trust Engineering.
YouTube channelDiscover more insights and resources on our platform.
Visit Kryptomindz